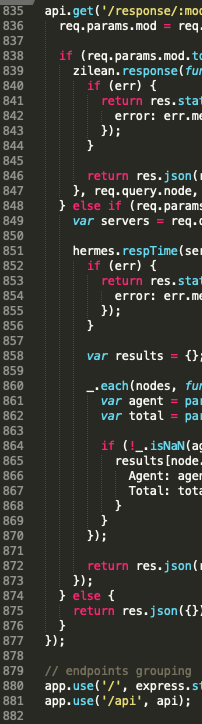
We leveraged OpenAI’s June 13 update to make our web app navigational assistant (“RiskPilot”) 5x faster and 20x cheaper.
While OpenAI stepped in the right direction with the Function Calling feature, we proved it has room to improve still.
Intro
At RiskThinking.AI, we initiated a project back in April to leverage OpenAI’s GPT model to build a navigational assistant (dubbed “RiskPilot”) for our web app. At the time, gpt-4-0314 was the only viable model since gpt-3.5-turbo-0301 doesn’t have “system steerability” (the ability to guide the conversation towards a specific subject or goal.)
Software QA (quality assurance), much like documentation, while important, often gets overlooked and buried down in the priority list when compared to research and development efforts.
While there are increasing efforts to automate the various aspects of software QA, many still require substantial effort to get meaningful values (such as writing unit- or end-to-end tests). However, we have sophisticated a few other fronts that can integrate into many projects with minimal setup.
Team collaboration must get a sense of each others’ whereabouts as quickly and accurately as possible. Usually, teams resort to recurrent meetings to get updates from each other.
But meetings are not always the best way for this scenario:
Meetings are synchronous, so everyone has to wait before continuing for the others to finish.
Especially when communicating verbally, it is difficult not to misinterpret each others’ words.
It is challenging to scale up the team size because that would amount to more meetings and more probable misinterpretation of the updates.
It is challenging to work as a distributed team where members can reside in different time zones.
Automation is not a binary thing. We rarely go from manual to fully autonomous with one switch. Just like software development itself, it often requires iterative revisions, with some craftsmanship and never-enough imaginations.
A case I would love to share is our 8-month and counting journey we took to automate our release notes process.
This year, I have made 60% more git commits than last year, objectively more feature development, without burning any extra time.
During the same period, I have kept my 11PM - 7AM sleep routine, contributed more supportive tasks at work such as cultural development, and maintained longer streaks on Duolingo.
All of the above has been possible thanks to problem breakdown. It is a common technique that applies to almost all types of knowledge work, which comes with some great benefits.
Solutions become easier to review
In my case, each commit represents the solution to a less scoped problem. This results in faster review time, and more constructive suggestions from reviewers.
On the opposite, when a single solution covers too many grounds, it would take much more time and effort to review, so the agility of development takes a hit. Even worse, reviewers would say “screw it” and blindly approve the behemoth solution, defeats the whole purpose of peer reviewing and fast-track derailing product quality to the netherworld.
Interruptions become more manageable
Suppose you need 2 hours of contiguous time to solve a large problem. During that process, unfortunately, you may get interrupted. Those interruptions will cost you a lot of time to switch your mental state back into the zone.
However, if you break such a problem down to 5 smaller ones, on average, each will need just about 30 minutes. 30 minutes of uninterrupted time is much easier to come by than 2 hours.
Even if you do get interrupted in that case, since each problem is about 1/5 complex of the original one, it would probably cost just 1/5 of the time to recover from the interruption. Simple math. Your short attention span will thank you for that too.
Helps to define better scopes for faster iterations
In an ideal world, you can pursue after your inner perfectionism without consequences. But in reality, there is always a decision to be made on when to stop pushing further. Otherwise, it may result in your time running out, or budget running dry, or blocking more of your teammates, or maddening more of your clients or stakeholders. You certainly do not want any of those.
So by breaking down larger problems down to smaller scopes, it often becomes easier to realize which ones can be deferred, or even dropped. At Basecamp, they call it Scope Hammering.
Helps to create momentum and build morale
Smaller solutions for smaller problems give faster wins. Faster wins create a healthy momentum to carry you forward and build positive morale.
Final Remark
Every real-world technique comes with tradeoffs. For this one, it’s the time overhead. The less experienced you are in the domain, the more significant that overhead can be. But given the benefits, it’s well worth it.
So stop chewing through that complex problem, go ahead and break it down.
Acknowledgements
Thanks to my wonderful coworkers at EQ Works for reviewing and breaking down this article.
Also thanks to Rain WZQ for the amazing illustrations.
Code structure can be an important factor of a clean, well-organized codebase that is less intimidating to a new maintainer, and pleasant to work with for everyone. When done right, it can even beat a thousand word doc.
In my experience, the significance of code structure is either overlooked or over-engineered from the beginning. Both would supercharge the build-up of technical debts and sometimes could lead to a dead project sooner than you can say “refactor”.
By following a couple of simple conventions, we can make any project, almost language agnostically, better structured.
Make the filesystem work for you
First, make the filesystem work for you, not the other way around. You want the readers of the code to think as less as possible on how and where to locate the relevant code they’re looking for. Modern tools such as IntelliSense make this relative unessential, but we cannot assume everyone has them available all the time.
This is more important if you work with a less opinionated stack or framework. In such a case, keeping a sane structure of files and folders would minimize frictions between maintainers, and across its development lifecycles.
There is no fixed “best way” to structure files and folders. But it’s important to pick one and stick to it.
For example, A Python API server project written in Flask may have a structure as below:
In this example, comments are among the modules that are at the same level as users and posts. But by itself, it’s a file, while the other two are folders. I’ll explain more about this in the next point.
Progressive Refactoring
When you start on a new project or a new feature of a given project, it’s not a bad idea at all to put everything in one file. All until its size grows to a point that makes it hard to navigate through, then we start to divide.
This time we’ll take an Express.js based single-file router as a starting point, and gradually refactor it to a more manageable form.
We’ll start with
1 2
./src/ # project root +-- app.js # entry point
We’ll assume the content of app.js to be something like https://github.com/EQWorks/ws-product-nodejs/blob/master/index.js. It’s a nice little web server that serves some PostgreSQL driven queries, everything in one file with no more than 100 lines of code. Short, sweet, and everything within (one file) short reach.
But soon the project would grow into something like:
Navigating through this would be a nightmare and you can hear your inner self screaming “refactor! refactor now!”. So let’s refactor this, progressively.
$ mkdir app && mv app.js app/index.js
1 2 3
./src/ # project root +-- app/ | +-- index.js
The first action is to stop the bleed by turning the app.js file into a package form. This does not make the existing code any more pleasant than before, but any new changes will have more leg room to expand on while keeping usage of the entire module the same:
1 2
// the usage of 'app' stays the same as before const app = require('./src/app')
Then you can wield your refactor ax whenever and wherever you can, all in a naturally scoped package form app/ that wraps all the implementation details and groupings without breaking the API. At some point, the structure could look like:
The evolution of the packages, sub-packages, sub-sub-packages, etc., all leverages the language’s filesystem-based package resolution mechanism (in this case Node.js, but similar with many), thus keeping the structure intuitive no matter how deep the structure tree goes, as long as the basic understanding of such mechanism is shared in common.
From within the code perspective, there are many strategies to divide and group. I like to keep as many things as pure functions as possible and keep them in an util.js module, or util/ (sub-)package. They can also be ./src/feature/util which is “local” to the given feature; or when a portion’s usage becomes common enough, refactored out to be a part of the “global” ./src/util. But that’s just one strategy among many. More discussions around this topic in the next point.
Grouping Conventions
No matter how much we leverage the filesystem based package resolution mechanism, there would always come the inevitable human-opinion based disputes. Developer A likes to call data interactions queries, while developer B prefers interfaces. Pick any, and stick through.
It is paramount though, not to confuse the readers of the code with misleading grouping. For instance, coming as a deeply experienced Ruby on Rails developer, it’s in their nature to group things by models, views, and controllers. But to adopt such grouping, in a more Sinatra-like stack (like Python Flask and Express.js from above), it is more important to communicate with the rest of the maintainers what belongs to where, so a view related functionality does not appear in the controllers group.
Or, simply follow a more natural convention. In the context of a web application, group by intended URLs the route handlers listen to would be an excellent way.
For instance, you would have two versions of the APIs, and a few API endpoint groups (the RESTful APIs term is “resources”):
1 2 3 4 5 6 7 8
GET /v1/users GET /v1/users/:id POST /v1/users DELETE /v1/users # ...and more GET /v2/comments GET /v2/comments/:id # ...and more
Why not map that naturally to your files structure?
1 2 3 4 5 6 7 8 9
./src/ # project root +-- v1/ # v1 API endpoints | +-- users/ # users group/resource | | +-- interface.js # db related queries/interface | | +-- index.js # router | # ... more +-- v2/ # v2 API endpoints | +-- comments.js # comments group/resource | # ... more
This way, when a non-technical person complains that “users dashboard have X glitch in v1”, the developer can just go into ./src/v1/users, and have a much smaller scope to deal with, without spending much valuable brain-cycle on pinning where things are.
Final Remarks
All of the above conventions are quite loose and are intentionally kept so. This is because every stack has its own set of ground rules to follow and best practices to base on. Also, it is meant to be adapted with personal preferences to not overshadow but to signify your, or your team’s style. Furthermore, in this highly evolving world of software, to keep these conventions loosely and naturally applied would allow for the projects to evolve along.
Hopefully, by adopting some or all of the above conventions, and by adapting them with your personal preferences, you get to enjoy programming even more.
Don’t trust your password on a system that has no multi-factor authentication mechanism, especially ones that allow the change of the ID (email in this case) of your login without rigorous checks; EVEN MORE SO if you have your financial service access/information (such as credit card) associated to it.
Update (Sep 07, 2018)
The account was recovered. That means I’m gladly proven wrong by DoorDash about not having sufficient logs to trace back. Thanks DoorDash.
Lately I’ve been leveraging the “serverless” architecture often. I like its statelessness, the predictable cost factor, the simplicity of development and deployment, etc. It just fits for systems that are event-driven. It’s already a strong tool that is being used by many live products, yet still steadily being improved by providers and the community on aspects such as cold-start time and time-to-live. Not to mention frameworks such as serverless and apex further spoil us with ease of utilization.
There are also many technical reasons one can use to argue against using this architecture. Job security for certain overly-specific professions aside, at the end of the day, it should depend on use cases and automation requirements.
However, one of my rationale to justify the use of this architecture, as mentioned in the title, is related to attention span.
In today’s world, it is increasingly hard to be exempted from having a short attention span, which is often caused by constant interruptions of thought process and work-flow.
The interruptions may come from your co-workers that don’t understand why it’s not optimal to tap on your shoulder while you are in the “zone”.
The interruptions may come from your S.O. or close family member who brings up some important matter in your life while you’re trying to organize your thoughts on a nested for-loop.
The interruptions may even come from your own self-distractions – social networks, exciting announcements, or simply an accidental overhearing of topics that can suddenly pull you out your chair, so you can eagerly express your expert opinion.
Unless your work, your life, and yourself can all discipline and behave, having a short attention span is almost unavoidable.
There are rare developers who have adapted or been blessed to have a large enough reservoir of memory, and nimble enough brain power to handle quick and short context switches. If you are, or work with, one of these, congratulations! Some call them “10x” developers, I believe they’re truly genius.
Unfortunately, the vast majority of us aren’t.
So here comes the beauty of working with the serverless architecture. By its design and its common limits, the software you deploy serverlessly are hopefully simple and small. That’s why providers name their direct serverless offering as “Lambda”, or “Functions”, and encourage developers to write pure, stateless, stable input-output functions that often focus on one thing at a time. That naturally leads to simpler and smaller of the program that needs to be written (don’t be too extreme though). And that means shorter tasks that fit better in our shorter attention spans.
Now, before I’m accused of being a sales person of certain provider, or a fan-boy of the architecture, let me lay it out for you what’s in it for the providers – smaller pieces = more services needed to solve real-world problems = more usage fees $$$. Simple.
So to avoid being ripped off by naively hopping on the hype-train, a new challenge for developers who work with serverless architecture is to figure out a good balance for each service to maximize processing done per billable resource, while keep the logic simple enough or just stateless. That’s not always easy, because it often requires assessment of other services that it connects with. In the older times (or larger organizations), this type of duty falls on the hand of dedicated architects, which is a profession that’s increasingly obsolete in the younger and smaller organizations (and rightfully so).
“Serverless” is far from being the silver-bullet answer to all problems, it still requires fine tinkering and craftsmanship.
But my point stands, that in a world full of distractions, the naturally simpler, smaller, and often stateless functions help greatly in solution composition, as well as mitigating interruptions coming from whatever angle.
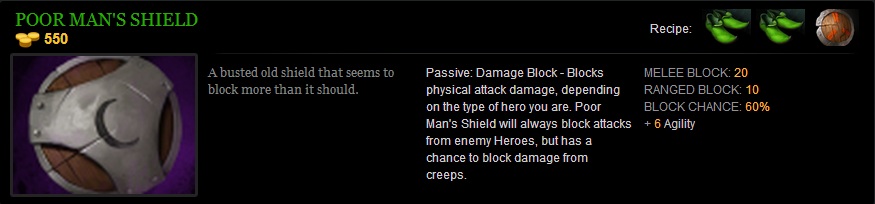
If you’ve played Dota, then you’d know an item called Poor Man’s Shield. Without getting too much into the meta and expose my laughable understanding of the game, the item is mostly about cost efficient way to deal with relatively tough situations in the early game, without the late game resources to go for a more luxurious option right away (except when you can stomp in early game against noobs like me).
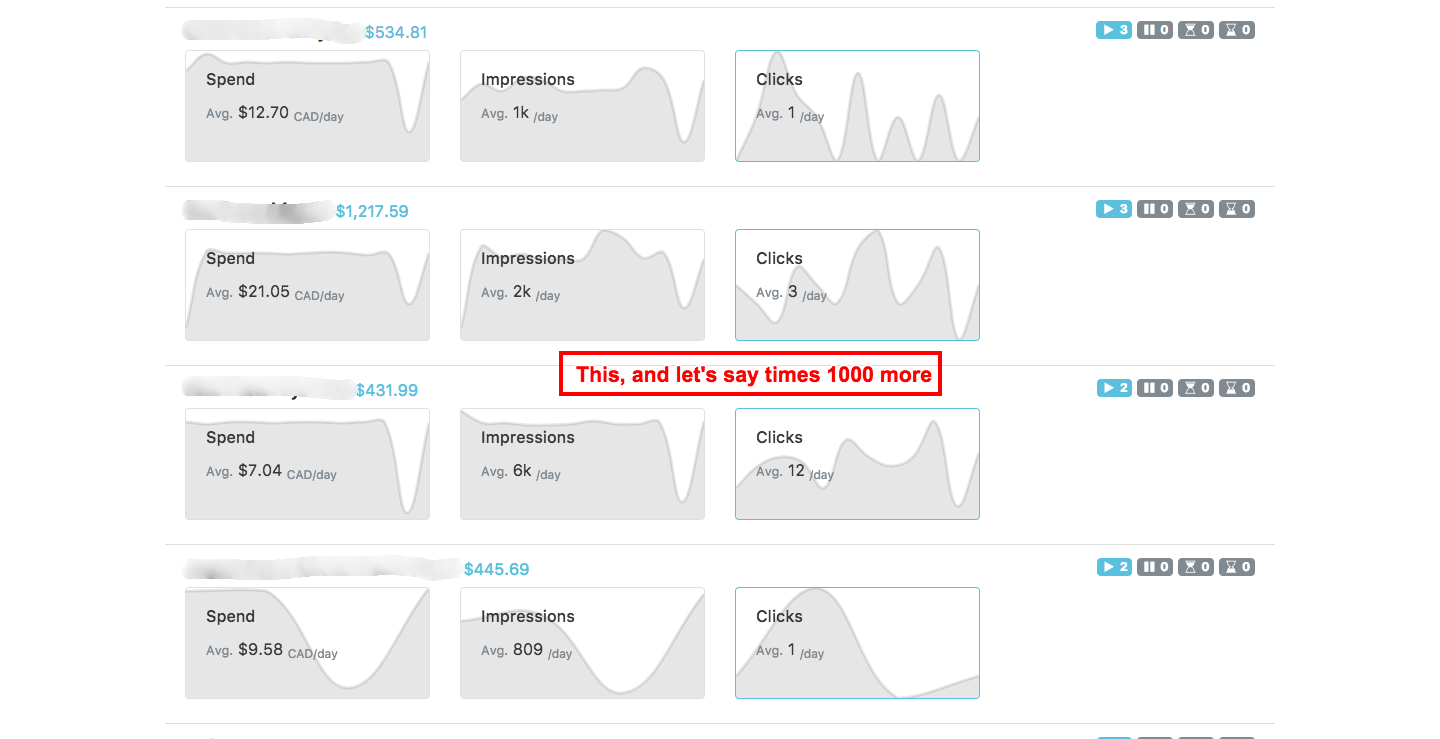
In web development, there can be tough situations as well. One situation I encountered recently was to load potentially thousands of items each with multiple charts on a single page, in a nutshell:
In this post, I’m going to walk through my steps of developing the poor man’s approach to handle the tough situation. For examples below, we are going to utilize Vue.js v2 as the data binding layer, and Chart.js v2 for chart.
This works. However it becomes royally painful to load when you have so many items as the situation I described earlier. In fact, just a mere hundred of such items on a single page already causes unpleasant amount of time to render while showing a blank page, and blocking all user interactions except inviting end users to force close the browser/tab due to frustration (and probably never getting them back). Such horror is not tolerable on today’s internet.
Be Asynchronous
One way we can make this better is to explicitly instruct the component to asynchronously initialize the chart through the use of setTimeout:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
var app = newVue({ //... other configurations components: { chart: { //... same component configurations as above mounted: function() { var self = this; // asynchronously initialize the chart setTimeout(function() { self.render(); }, 0); } } } });
This approach effectively causes Vue to render the charts in the “next” update cycle. It makes the UI a bit less painful to use as there can be some “primer” contents rendered, which usually exhibit as a part of the parent elements that hold the chart component. However, this is not good enough, as the deferred update cycle would still block the whole UI. This is especially bad when the page offers many items in a list fashion that the users would want to either search with CTRL/CMD + F or scroll down for items that are out of the current view. Besides, it’s very wasteful to render things that cannot even be seen yet.
Be Lazy
This leads to a tried and proven technique many refer to as “lazy-loading”. With so many years of such technique being matured, and thanks to the ever so successful open source community, one can easily pick a robust library that does it well while being delightfully simple to use. The following is an approach with one such library called ScrollReveal:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
var sr = ScrollReveal(); var app = newVue({ //... other configurations components: { chart: { //... same component configurations as above mounted: function() { var self = this; sr.reveal(self.$el, { afterReveal: self.render }); } } } });
It’s pretty amazing now, the component rendering get deferred until they are needed by the end users.
Extra
After handling the situations for the sake of end users, let’s make a final touch to give some options for the users of this component to have control over the render flow, for example:
var sr = ScrollReveal(); var app = newVue({ //... other configurations components: { chart: { //... same component configurations as above props: [ 'height', 'data', 'options', 'type', 'flow'// let's add a 'flow' parameter ], mounted: function() { var self = this; if (self.flow == 'sync') { self.render(); } elseif (self.flow == 'async') { setTimeout(function() { self.render(); }, 0); } else { sr.reveal(self.$el, { afterReveal: self.render }); } } } } });
The flow parameter allows 3 modes, let’s go by imaginary use cases:
sync would be used when this chart component is nested under another component (which hopefully already applies some sort of render deferring optimization similar to what we’ve done thus far), and requires the chart to visually appear at the same time as its parent component
async is very similar to sync, except that we don’t require the chart to visually appear at the exact same moment as its parent component.
The third and the default mode would be the self-contained optimal approach that we worked out from above.
There’s room for more sophistication. One can wrap the above into an easy-to-use custom directive or wrapper component, or even directly make it into Vue.js, making it more of an “end game” approach. With some twist, this approach can also be adapted into other choices of data binding layer and chart library.
But there’s always the option to employ the poor man’s approach – simple, effective, easy to understand and not too shabby to apply to any existing applications of any scale.
Programming can be enjoyable, but not always so. I bet even those who claim to be the most passionate about programming suffer from impossible deadlines, technical difficulties and other causes. As a programmer, I certainly don’t want to have my final moment like this:
You see, when you lie on your death bed, you will look deep into your wife’s eyes, and think of all those lovely moments you spend in Visio drawing UML diagrams and writing clean, simple and maintainable code… Stack Exchange User 11170 - https://programmers.stackexchange.com/a/114888/95830